
How does Teacher Forcing work?
How does Teacher Forcing work?
NOTE Original Author for this Article: https://towardsdatascience.com/what-is-teacher-forcing-3da6217fed1c
Have you ever had math exam questions that consist of multiple parts, where the answer for part (a) is needed for the calculation in part (b), answer for part (b) is needed for part (c), and so on? I always pay extra attention to these questions because if we get part (a) wrong, then all the subsequent parts will most likely be wrong as well, even though the formulas and the calculations are correct. Teacher Forcing remedies this as follows: After we obtain an answer for part (a), a teacher will compare our answer with the correct one, record the score for part (a), and tell us the correct answer so that we can use it for part (b).
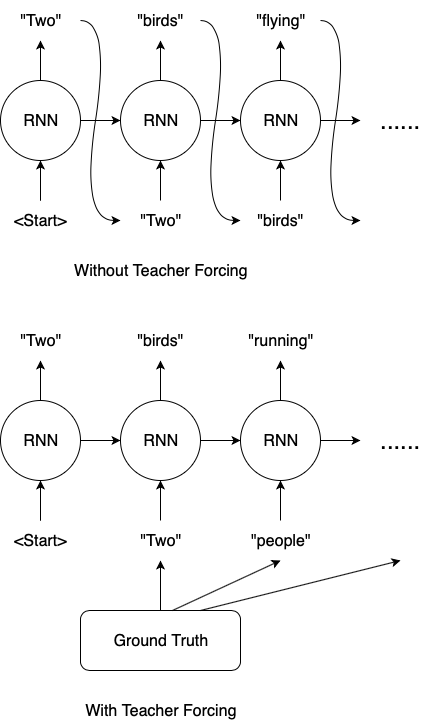
The situation for Recurrent Neural Networks that output sequences is very similar. Let us assume we want to train an image captioning model, and the ground truth caption for the above image is “Two people reading a book”. Our model makes a mistake in predicting the 2nd word and we have “Two” and “birds” for the 1st and 2nd prediction respectively.
- Without Teacher Forcing, we would feed “birds” back to our RNN to predict the 3rd word. Let’s say the 3rd prediction is “flying”. Even though it makes sense for our model to predict “flying” given the input is “birds”, it is different from the ground truth.
- On the other hand, if we use Teacher Forcing, we would feed “people” to our RNN for the 3rd prediction, after computing and recording the loss for the 2nd prediction.

Pros and Cons of Teacher Forcing
Pros:
Training with Teacher Forcing converges faster. At the early stages of training, the predictions of the model are very bad. If we do not use Teacher Forcing, the hidden states of the model will be updated by a sequence of wrong predictions, errors will accumulate, and it is difficult for the model to learn from that.
Cons:
During inference, since there is usually no ground truth available, the RNN model will need to feed its own previous prediction back to itself for the next prediction. Therefore there is a discrepancy between training and inference, and this might lead to poor model performance and instability. This is known as Exposure Bias in literature.